
* 데이터 사전
- 데이터 사전이란?
: 데이터베이스를 구성하고 운영하는데 필요한 정보
- 데이터베이스 테이블
- 사용자 테이블(user table)
- 데이터 사전(data dictionary)
=> 사용자가 데잍터 사전 정보에 직저 접근, 작업을 허용하지 않기 떄문에 데이터 사전 뷰를 제공
- 데이터 사전 뷰(data dictionary view) - 가상의 테이블
: DB를 구성하고 운영하는 데이터를 저장하는 특수한 테이블

- USER_접두어를 가진 데이터 사전
: 접속한 사용자가 소유한 객체 정보
<예시>
SELECT TABLE_NAME
FROM USER_TABLES;
- ALL_접두어를 가진 데이터 사전
: 접속한 사용자가 소유하거나, 사용을 허가받은 객체 정보
<예시>
SELECT OWNER, TABLE_NAME
FROM ALL_TABLES;
- DBA_ 접두어를 가진 데이터 사전
: 데이터베이스 관리 권한을 가진 사용자가 조회가능
<예시>
- DBA_TABLES 조회
SELECT * FROM DBA_TABLES;=> 에러 뜸 table or view does not exist
SYSTEM 계정으로 접속하면 조회 가능

=> 최고 관리자만 접근 가능
- DBA_USERS사용 (SYSTEM 계정 롤 SYSDBA)
SELECT *
FROM DBA_USERS
WHERE USERNAME = 'HR';
* 더 빠른 검색을 위한 인덱스
- 인덱스란?
: 데이터 검색 성능 향상을 위해 테이블 열에 사용하는 객체
- 데이터 검색 방식
- Table Full Scan : 테이블 데이터를 처음부터 끝까지 검색해 찾는 방식
- Index Scan : 인덱스를 통해 데이터 찾는 방식
<예시>
- 인덱스 정보 보기(기본 계정)
SELECT *
FROM USER_INDEXES;
- 인덱스 컬럼 정보 보기(기본 계정)
SELECT *
FROM USER_IND_COLUMNS;
- 인덱스 종류
| 방식 | 사용 |
| 단일 인덱스(single index) | CREATE INDEX IDX_NAME ON EMP(SAL); |
| 복합 인덱스(concatenated index) 결합 인덱스(composite index) - 두 개 이상 열로 만들어지는 인덱스 - WHERE 절의 두 열이 AND연산으로 묶이는 경우 |
CREATE INDEX IDX_NAME ON EMP(SAL, ENAME,...); |
| 고유 인덱스(unique index) - 열에 중복 데이터가 없을 때 사용 - UNIQUE 키워드를 지정하지 않으면 비고유 인덱스(non unique index)가 기본값 |
CREATE UNIQUE INDEX IDX_NAME ON EMP(EMPNO); |
| 함수 기반 인덱스(function based index) - 열에 산술식 같은 데이터 가공이 진행된 결과로 인덱스 생성 |
CREATE INDEX IDX_NAME ON EMP( SAL * 12 + COMM); |
| 비트맵 인덱스(bitmap index) - 데이터 종류가 적고 같은 데이터가 많이 존재할 때 주로 사용 |
CREATE BITMAP INDEX IDX_NAME ON EMP(JOB); |
- 인덱스 생성
- 기본 형식

<예시>
- EMP 테이블의 SAL 열에 인덱스 생성
CREATE INDEX IDX_EMP_ENAME
ON EMP(ENAME);
- 생성된 인덱스 조회
SELECT * FROM USER_IND_COLUMNS
WHERE TABLE_NAME = 'EMP';
- 인덱스 삭제
DROP INDEX 인덱스명;
<예시>
DROP INDEX IDX_EMP_ENAME;
* 테이블처럼 사용하는 뷰
- 뷰란?
: 가상 테이블(virtual table)로 부르는 뷰(view)는 하나 이상의 테이블을 조회하는 SELECT문을 저장한 객체
- 뷰의 사용 목적
- 편의성 : SELECT문의 복잡도 완화
- 보안성 : 테이블의 일부 데이터만 노출
- SELECT문 이외에 데이터 조작어(삽입, 수정, 삭제) 사용도 가능하지만 이로 인해 적합하지 않은 데이터가 생길 수도 있으므로 자주 사용하진 않는다.
- 데이터를 따로 저장하는 것이 허용되는 구체화 뷰(materialized view)도 존재
<예시>
- 뷰 생성
SELECT EMPNO, ENAME, JOB, DEPTNO
FROM EMP
WHERE DEPTNO = 20;
- 조회
--뷰
SELECT *
FROM VW_EMP20;
--서브쿼리
SELECT *
FROM(SELECT EMPNO, ENAME, JOB, DEPTNO
FROM EMP
WHERE DEPTNO = 20);
- 뷰 생성

① 같은 이름 뷰 있으면 대체 생성
② 뷰가 저장할 SELECT문의 기반 테이블이 존재하지 않아도 강제로 생성
③ 뷰가 저장할 SELECT문의 기반 테이블이 존재할 경우에만 생성
④ 생성할 뷰 이름 지정
⑤ SELECT문에 명시된 이름 대신 사용할 열 이름 지정
⑥ 생성할 뷰에 저장할 SELECT문 지정
⑦ 지정한 제약 조건을 만족하는 데이터에 한해 DML작업 가능하도록 뷰 생성
⑧ 뷰의 열람, 즉 SELECT만 가능하도록 뷰 생성
<예시>
- sys 계정에 뷰 생성 권한 부여(SQL * PLUS)
SQL> connect sys/oracle as sysdba;
Connected.
SQL> GRANT CREATE VIEW TO HR;
- 뷰 생성(SYS계정)
CREATE OR REPLACE VIEW VW_EMP20
AS (SELECT E.EMPNO, E.ENAME, JOB, D.DEPTNO, D.DNAME
FROM EMP E, DEPT D
WHERE E.DEPTNO = D.DEPTNO
AND E.DEPTNO = 20);
- 뷰 조회
SELECT * FROM VW_EMP20;
- 뷰 삭제
- 기본 형식
DROP VIEW 뷰 이름;
<예시>
- 뷰 삭제
DROP VIEW VW_EMP20;
- USER_VIEW로 데이터 사전 조회
SELECT * FROM USER_VIEWS;
=> 삭제됨
- 인라인 뷰를 사용한 TOP-N SQL문
- 인라인 뷰(inline view) : SQL문에서 일회성으로 만들어서 사용하는 뷰
- SELECT문의 서브쿼리
- WITH절에서 미리 이름 정의해두고 사용하는 SELECT문
<예시>
-- ROWNUM 추가로 조회
SELECT ROWNUM, E*
FROM EMP E;
=> ROWNUM은 EMP테이블에 존재하지는 않지만 출력은 된다.
- *ROWNUM : 의사 열(pseudo column)이라고 하는 특수 열로 데이터가 저장되는 실제 테이블에 존재하진 않지만 특정 목적을 위해 저장되어 있는 열처럼 사용 가능한 열(출력 가능)
- *ROWNUM 열 데이터 번호 : 테이블에 저장된 행이 조회된 순서대로 매겨진 일련번호
- ROWNUM과 ORDER BY절
SELECT ROWNUM, E.*
FROM EMP E
ORDER BY SAL DESC;
=> ROWNUM의 번호 순서가 뒤죽박죽 됨 -> ROWNUM 일련번혼는 ORDER BY 절 이전에 생성되기 때문
- 인라인뷰(서브쿼리 사용)
SELECT ROWNUM, E.*
FROM (SELECT *
FROM EMP E
ORDER BY SAL DESC) E;=> 서브쿼리문에서 정렬이 먼저 실행되고 SELECT문에서 ROWNUM이 부여됨

- 인라인뷰(WITH절 사용)
WITH E AS (SELECT * FROM EMP ORDER BY SAL DESC)
SELECT ROWNUM, E.*
FROM E;=> 서브쿼리를 E라는 별칭 지정해줌
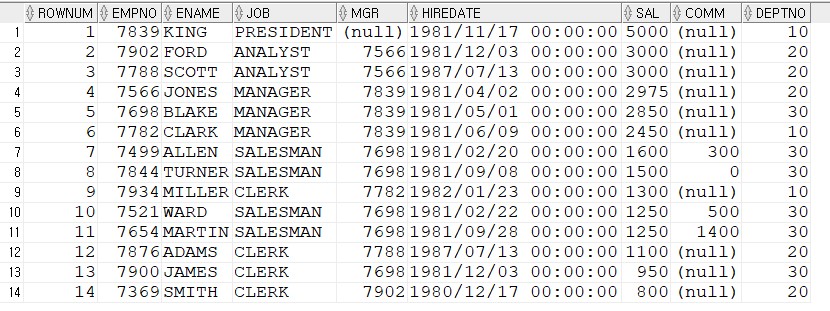
=> 결과값 동일
- 인라인 뷰로 TOP-N 추출(서브쿼리 사용)
SELECT ROWNUM, E.*
FROM (SELECT *
FROM EMP E
ORDER BY SAL DESC) E
WHERE ROWNUM <= 3;
=> ROWNUM 1~3까지 출력
- 인라인 뷰로 TOP-N 추출(WITH절 사용)
WITH E AS (SELECT * FROM EMP ORDER BY SAL DESC)
SELECT ROWNUM, E.*
FROM E
WHERE ROWNUM <= 3;
=> 결과 값 동일
✔️페이지네이션
: 대량의 데이터나 긴 목록을 여러 페이지로 나누어 표시하는 기술
=> 일련번호는 무조건 1을 포함해야한다. 3을 특정하거나 4-7 범위를 출력하는 거 불가능
따라서 실제 실무에서 페이지네이션 경우에는 ROWNUM까지도 인라인 뷰로 만들어 사용한다.
SELECT * --3. 일련번호 범위 설정
FROM (SELECT ROWNUM AS ROWN, E.* --2. ROWNUM 일련번호 부여
FROM(SELECT * --1.SAL기준 정렬
FROM EMP E
ORDER BY SAL DESC) E)
WHERE ROWN BETWEEN 6 AND 10;
* 규칙에 따라 순번을 생성하는 시퀀스
- 시퀀스란?
: 오라클 데이터베이스에서 특정 규칙에 맞는 연속 숫자를 생성하는 객체(번호 생성기)
-> 지속적이고 효율적인 번호 생성이 가능
exx) 은행 대기 순번표
- 시퀀스 생성

① 생성할 시퀀스 이름 지정 - 필수
(아래 절 지정 안했으면 1부터 시작해 1만큼 증가하는 시퀀스 생성)
② 시퀀스에서 생성할 번호의 증가 값(기본값 1)
③ 시퀀스에서 생성할 번호의 시작 값(기본값 1)
④ 시퀀스에서 생성할 번호의 최댓값 지정
NOMAXVALUE로 지정했을 경우
- 오름차순이면 10²⁷
- 내림차순이면 -1
⑤ 시퀀스에서 생성할 번호의 최솟값 지정
NOMINVALUE로 지정했을 경우
- 오름차순이면 1
- 내림차순이면 10⁻²⁶
⑥시퀀스에서 생성한 번호가 최댓값에 도달했을 경우
- CYCLE이면 시작 값에서 다시 시작
- NOCYCLE이면 번호 생성 중단
- 추가 번호 생성하면 오류 발생
⑦시퀀스가 생성할 번호를 메모리에 미리 할당해 놓은 수 지정(옵션 모두 생략하면 기본값 20)
- NOCACHE는 미리 생성하지 않도록 설정
<예시>
- DEPT_SEQUENCE 테이블 생성
CREATE TABLE DEPT_SEQUENCE
AS SELECT * FROM DEPT WHERE 1 <> 1;
SELECT * FROM DEPT_SEQUENCE;
- 시퀀스 생성
CREATE SEQUENCE SEQ_DEPT_SEQUENCE
INCREMENT BY 10
START WITH 10
MAXVALUE 90
MINVALUE 0
NOCYCLE
CACHE 2;
- 시퀀스 확인
SELECT *
FROM USER_SEQUENCES;
- 시퀀스 사용
- CURRVAL - 시퀀스 마지막 생성 번호
- NEXTVAL - 다음 번호 생성
<예시>
- 시퀀스에서 생성한 순번 사용한 INSERT문 실행(NEXTVAL)
INSERT INTO DEPT_SEQUENCE (DEPTNO, DNAME, LOC)
VALUES(SEQ_DEPT_SEQUENCE.NEXTVAL, 'DATABASE', 'SEOUL');
INSERT INTO DEPT_SEQUENCE (DEPTNO, DNAME, LOC)
VALUES(SEQ_DEPT_SEQUENCE.NEXTVAL, 'NETWORK', 'SEOUL');
SELECT * FROM DEPT_SEQUENCE;
- 가장 마지막으로 생성된 시퀀스 확인(CURRVAL)
SELECT SEQ_DEPT_SEQUENCE.CURRVAL
FROM DUAL;
- 시퀀스에서 생성한 순번 반복 사용하여 INSERT문 실행
INSERT INTO DEPT_SEQUENCE (DEPTNO, DNAME, LOC)
VALUES(SEQ_DEPT_SEQUENCE.NEXTVAL, 'DATABASE', 'SEOUL'); --7번 더 실행
SELECT * FROM DEPT_SEQUENCE ORDER BY DEPTNO;
=> 시퀀스 최댓값 90에 도달하면 더이상 시퀀스 번호 생성 불가
- 시퀀스 수정 - ALTER
: ALTER 명령어
- 기본 형식
ALTER SEQUENCE 시퀀스 이름
[INCREMENT BY n]
[MAXVALUE n | NOMAXVALUE]
[MINVALUE n | NOMINVALUE]
[CYCLE | NOCYCLE]
[CACHE n | NOCACHE]=> START WITH값은 변경 불가
<예시>
- 시퀀스 옵션 수정
ALTER SEQUENCE SEQ_DEPT_SEQUENCE
INCREMENT BY 3
MAXVALUE 99
CYCLE;SELECT * FROM USER_SEQUENCES;
- 수정한 시퀀스 사용해 INSERT문 실행
INSERT INTO DEPT_SEQUENCE (DEPTNO, DNAME, LOC)
VALUES (SEQ_DEPT_SEQUENCE.NEXTVAL, 'DATABASE', 'SEOUL');
SELECT * FROM DEPT_SEQUENCE ORDER BY DEPTNO;
=> 18행부터 3씩 증가해 99까지 생성됨
=> 추가된 열의 DEPTNO 값이 99가 되면 다시 0부터 3씩 증가된다. (10행까지 증가됨)
- 시퀀스 삭제 - DROP
- 기본 형식
DROP SEQUENCE SEQ_DEPT_SEQUENCE;
SELECT * FROM USER_SEQUENCES;
=> SEQ_DEPT_SEQUENCE 사라짐
+) 시퀀스는 삭제가 되어도 시퀀스를 사용하여 추가된 데이터는 삭제되지 않는다.
* 공식 별칭을 지정하는 동의어
- 동의어란?
: 객체 이름 대신 사용할 수 있는 다른 이름으로 다양한 SQL문에서 사용 가능
- 테이블 별칭과 유사하다고 볼 수 있지만 동의어는 오라클 데이터베이스에 저장되는 객체로 일회성이 아니다.
- 동의어 생성 역시 권한을 따로 부여해야 한다.
- 기본 형식

① 동의어를 데이터베이스 내 모든 사용자(본래 객체의 사용 권한 있는)가 사용할 수 있도록 설정
(생략하면 생성한 사용자만 사용 가능)
② 생성할 동의어 이름 - 필수
③ 생성할 동의어의 본래 객체 소유 사용자 지정(생략하면 현재 접속한 사용자로 지정)
④ 동의어를 생성할 대상 객체 이름 - 필수
<예시>
-권한 부여하기(SQL * PLUS)
SQL> connect sys/oracle as sysdba;
Connected.
SQL> GRANT CREATE VIEW TO HR;=> sys계정으로 접속하여 hr계정에 권한을 부여
- 동의어 생성
<예시>
- EMP 테이블의 동의어 생성(SQL Developer)
CREATE SYNONYM E
FOR EMP;SELECT * FROM E;
- 동의어 삭제
- 기본 형식
DROP SYSNONYM 동의어 이름;
<예시>
DROP SYNONYM E;
'개발 공부 > Oracle' 카테고리의 다른 글
| [Oracle] - 사용자, 권한, 롤 관리 (0) | 2023.12.11 |
|---|---|
| [Oracle] - 제약조건 (0) | 2023.12.11 |
| [Oracle] - 데이터 정의어 (0) | 2023.12.08 |
| [Oracle] - 트랜잭션 제어와 세션 (0) | 2023.12.07 |
| [Oracle] - 데이터 조작어 (0) | 2023.12.06 |