[DB] - 데이터 베이스 설계와 정규화
* 데이터 베이스 개념어
엔터티 (Entity)
- 데이터가 수집되고 저장되는 최소단위
- 물리 데이터 모델에서 테이블(Table)로 정의
인스턴스(Instance)
- 각 테이블에 들어있는 데이터
- 물리 데이터 모델에서 로우(Row)로 정의
애트리뷰트(Attribute)
- 엔터티의 인스턴스의 특징을 설명
- 물리데이터 모델에서의 칼럼(Column)으로 정의
<예시>
- 엔터티: 학생
- 인스턴스: 홍길동, 김철수 (학생 엔터티의 구체적인 개체)
- 애트리뷰트: 학생 엔터티의 애트리뷰트로는 이름, 학번, 전공
* 데이터 베이스 설계
: 지속성을 요구하는 데이터의 논리 및 물리 모델을 정의하는 작업 수행
- 데이터 아키텍처를 구성하는 요소
- 개념적 데이터 모델
- 논리적 데이터 모델
- 물리적 데이터 모델
- 개념적 데이터 모델
- 내가 하고자 하는 일의 데이터 간의 관계를 구상한
- 엔터티-관계 다이어그램(Entity-Relationship Diagram, ERD)이나 UML(Unified Modeling Language)과 같은 도구를 사용하여 시각화

- 논리적 데이터 모델
- 구체화된 업무 중심의 데이터 모델
- 지속적 처리를 요구하는 객체(인스턴스 = 데이터)를 식별, 엔터티(테이블)로 정의
- 업무에 대한 Key, 속성, 관계 등을 표시
- 정규화 활동 수행
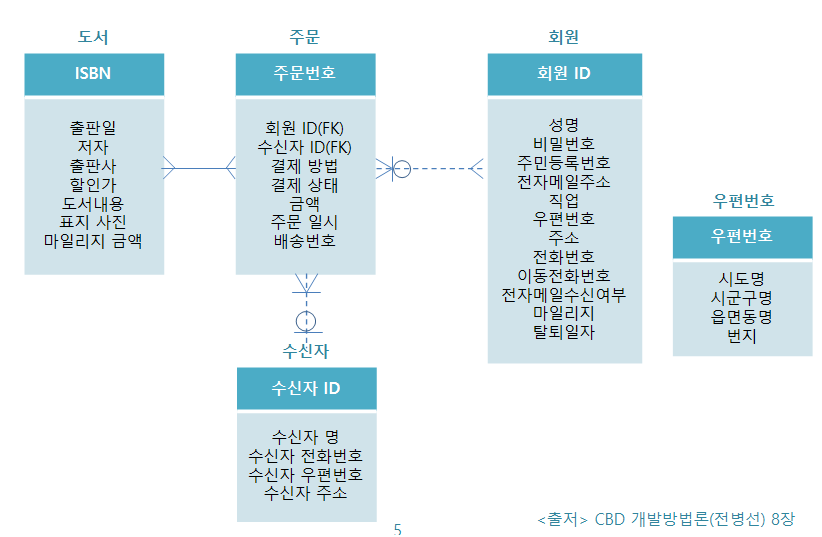
1. 엔터티 사이의 관계를 식별
- 카디널리티(Cardinality)
: 데이터베이스 설계에서 두 엔터티(테이블) 간의 관계에서 한쪽 엔터티의 레코드가 다른 쪽 엔터티와 어떻게 관련되어 있는지를 나타내는 개념
- 1 : 1 관계

- 1 : N 관계

- M : N 관계

=> 다 대 다 관계는 완성되지 않은 모델로 간주하기 때문에 1:N, N:1로 조정하는 작업(관계의 해소)이 필요하다

| 기수성 | 1대 1(one-to-one) |
| 1대 다(one-to-many) | |
| 다 대 1(many-to-one) | |
| 다대 다(many-to-many) | |
| 선택성 | 필수(mandatory) |
| 선택(optional) |
기수성 - 관계를 맺는 각 엔터티에 허용되는 엔터티 인스턴스의 개수를 지정하는 것
선택성 - 관계를 맺고 있는 하나의 엔터티가 다른 엔터티와는 독립적으로 존재할 수 있는지 여부를 지정
2. 각 엔터티에서 기본키와 외래키를 식별
- 식별자 관계
- 실선 표현
- 자식이 부모의 주 식별자를 외래 식별자로 참조해서 자신의 주 식별자로 설정
- 비식별자 관계
- 점선 표현
- 자식이 부모의 주 식별자를 외래 식별자로 참조해서 일반 속성으로 사용
- 키(key)
- 기본키(Primary key) - 엔터티(테이블)의 인스턴스(데이터 - 로우)를 유일하게 식별할 수 있는 값을 갖는 애트리뷰트(속성 - 컬럼)
- 외래키(Foreign key) - 자식 엔터티(테이블) 안에 존재하며 대응되는 부모 엔터티와의 관계를 형성하는 값을 갖는 애트리뷰트
- 복합키(Composite key) - 하나 이상의 애트리뷰트를 기본키로 하는 애트리뷰트 집합

✔️ERD 관계 표기법
- 관계선 각 측의 끝자락에 표기
- '|' 표시 - 반드시 있어야 하는 개체(필수)
- 'O' 표시 - 없어도 되는 개체(선택)
- '<' / '>' 표시 - 1 대 다에서 '다'


3. 정규화 수행
- 데이터베이스에서 중복된 데이터를 제거하도록 논리모델을 정제하는 과정
- 정규화는 데이터베이스를 여러 개의 테이블로 분할하고, 이들 테이블 사이의 관계를 정의하는 과정을 포함한다
- 이점
- 정보의 중복성 최소화
- 데이터 불일치 감소
- 데이터의 변경작업(삽입, 갱신, 삭제) 수행 속도 증가
- 정규화 단계

=> 제 N 정규형은 그 이전의 정규형을 모두 만족해야 한다.
✔️정규화 종류
제 1 정규형(1NF)
- 모든 도메인이 원자값으로만 구성
* 원자값 : 하나의 속성(칼럼)이 하나의 값만 가지는 것
<예시> - 고객 취미
- 제 1 정규형 불만족
| 이름 | 취미 |
| 김연아 | 인터넷 |
| 추신수 | 영화, 음악 |
| 박세리 | 음악, 쇼핑 |
| 장미란 | 음악 |
=> 여러개의 취미가 있으므로 제1 정규형 만족 안함
- 제 1 정규 만족(분해)
| 이름 | 취미 |
| 김연아 | 인터넷 |
| 추신수 | 영화 |
| 추신수 | 음악 |
| 박세리 | 음악 |
| 박세리 | 쇼핑 |
| 장미란 | 음악 |
제 2 정규형(2NF)
- 모든 속성의 부분적 종속이 없이 완전 함수 종속을 만족
*완전 함수 종속 : 오로지 기본키(PK)만으로 다른 속성이 결정
<예시>
- 제 2 정규형 불만족
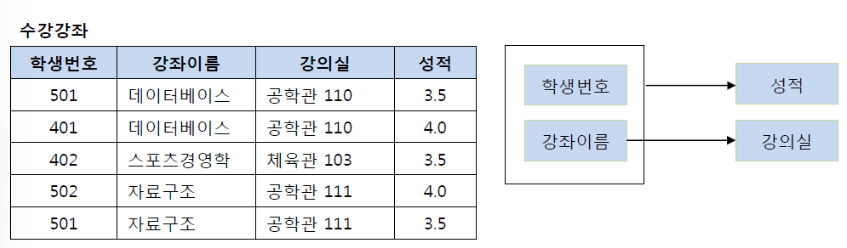
- 기본키(PK) : 학생번호 + 강좌이름 (복합키)
- 성적 결정 : (학생번호, 강좌이름) -> (성적)
- 강의실 결정 : (강좌이름) -> (강의실)
=> 강의실은 기본키의 부분집합(강좌이름)에 의해 결정되므로 테이블에서 강의실 분해
- 제 2 정규형 만족

제 3 정규형(3NF)
- 기본키를 제외한 속성들 간 이행 종속성이 없음
* 이행 종속성 : 'X → Y 이고 Y → Z 일 때, X → Z'인 경우
<예시>
- 제 3 정규형 불만족
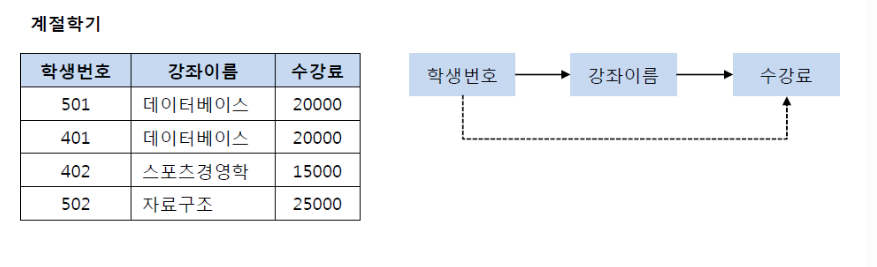
=> 이행 종속성이 있는 경우이므로 (학생번호, 강좌 이름) 테이블과 (강좌 이름, 수강료) 테이블로 분해해야 한다.
- 제 3 정규형 만족

보이스 / 코드 정규형 (BCNF)
: 모든 결정자가 후보키일 때, 결정자이면서 후보키가 아닌 것을 제거
<예시>
- 보이스 / 코드 정규형 불만족
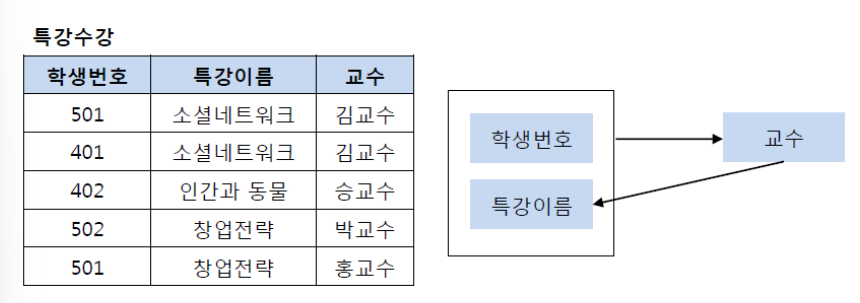
- 기본키 : 학생번호, 특강이름
- (학생번호, 특강이름) → (교수) 결정
- (교수) → (특강이름)
=> 교수는 결정자이지만 후보키가 아니다.
- 보이스 / 코드 정규형 만족

제 4 정규형(4NF)
: 다치 종속(MVD) 제거
* 다치 종속 : 다중값 종속이라고도 하며 같은 테이블 내의 독립적인 두 개 이상의 컬럼이 또 다른 컬럼에 종속되는 것
<예시>
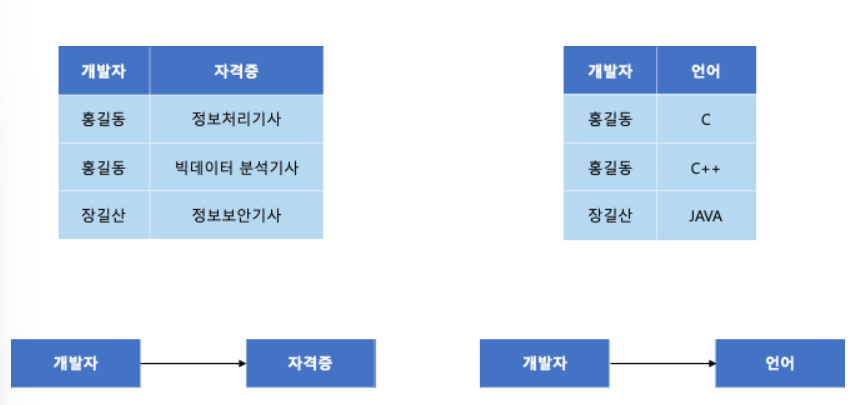
- 제 4 정규형 불만족

- 개발자 → 자격증
- 개발자 → 언어
=> 두가지 의존성을 가지므로 다치 종속이 존재
- 제 4 정규형 만족
제 5 정규형(5NF)
: 모든 조인 종속이 후보키를 통해서만 성립
* 조인 종속 : 하나의 릴레이션(테이블)을 여러개의 릴레이션으로 분해했다가 다시 조인했을 때 데이터 손실이 없고 필요없는 데이터가 생기는 것
<예시>
- 제 5 정규형 불만족

=> 데이터 손실은 없지만 불필요한 데이터 추가적으로 생겼음
- 제 5 정규형 만족

=> 분리
- 물리적 데이터 모델
- 최종적으로 데이터 베이스를 선택하고 실제 테이블을 만든다.
1. 논리 데이터모델을 물리 데이터 모델로 전환
| 논리적 DB 설계 | 물리적 DB 설계 | |
| 엔터티(Entity) | → | 테이블(Table) |
| 속성(Attribute) | → | 칼럼(Column) |
| 주식별자(primary identifier) | → | 기본키(primary key) |
| 외래식별자(foreign identifier) | → | 외래키(foreign key) |
| 인스턴스(Instance) | → | 로우(Row) |
=> 엔터티와 애트리뷰트를 각각 물리 데이터 모델의 테이블과 컬럼으로 맵핑시키고 1 대 1 관계와 다 대 다 관계를 해소시키는 작업
2. 데이터 최적화 수행
* 데이터 최적화 : 각 질의에 대하여 응답시간을 최소화하고, 네트워크 트래픽이나 디스크 입출력, 프로세서 시간 등을 최소화 함으로써 전체 데이터베이스 서버의 처리량을 최대화 하는 것
- 데이터 생성 최적화
- 데이터 추출 최적화
- 데이터 삭제 최적화
- 최적화의 방법 중 하나로 비정규화
=> 정규화가 과도하게 실행되면 효율이 너무 낮다. 이때 비정규화를 하여 하나의 테이블로 통합함으로써 조인의 수를 줄일 수 있다.
3. 데이터 무결성 설계
- 도메인 무결성 - 칼럼에 대하여 정확한 데이터 값의 범위를 지정하며, 널값이 허용되는지 여부를 결정
- 엔터티 무결성 - 테이블에 있는 모든 로우가 유일한 식별자 즉, 기본키 값을 가질 것을 요구
- 참조 무결성 - 부모 테이블의 기본키와 자식테이블의 외래키 사이의 관계가 항상 유지된다는 것을 보장
* 데이터 무결성 : 데이터의 일관성과 정확성
- 데이터 모델링 개념 참고 자료