
*데이터베이스의 개요
- 데이터베이스란?
데이터베이스(Database)
- 사전적 의미 - 여러 사람이 공유하여 사용할 목적으로 체계화하여 통합, 관리하는 데이터의 집합
- 방대한 데이터를 쉽게 검색하거나 찾을 수 있도록 체계적으로 분류 하고 정리해둔 정보의 집합
- 디지털화된 정보만 의미하는 것은 아님
DBMS(DataBase Management System)
- 데이터베이스는 DBMS라고 불리는 소프트웨어 시스템을 사용
- 효과적인 데이터 파일 관리와 운영을 위한 구조와 함께 인덱싱, 캐싱, 네트 워크 서버, 사용자 및 권한 관리, 백업/복원, 클러스터링 등 다양한 기능을 제공
- DBMS의 종류: Oracle, MySQL, IBM DB2, MS SQL 등
- 데이터베이스와 데이터베이스 관리 시스템인 DBMS는 다른 의미이지만 보통 데이터 베이스라고 하면 DBMS를 포함한 개념을 의미
데이터베이스의 일반적인 특징
- 데이터 중복을 최소화
- 데이터를 쉽게 공유
- 일관성, 무결성, 보안성이 유지
- 최신 데이터를 유지
- 데이터의 표준화가 가능
- 데이터의 논리적·물리적 독립성이 유지
- 데이터 접근이 용이
- 데이터 저장 공간을 절약할 수 있음
- 데이터베이스의 종류
관계형 데이터베이스(Relational DataBase Management System, RDBMS)
- 전통적이고 가장 보편적인 형태의 데이터베이스이며, 관계를 가지는 데이터 구조가 필요한 경우 가장 적합한 데이터베이스
- 테이블(Table): 칼럼과 로우 구조로 데이터 구조를 정의하고 관리함
- SQL(Structured Query Language): 데이터를 관리하는 질의어임. 특히 테이블과 테이블의 관계 지정을 통해 연관성 있는 데이터를 체계적으로 구조화할 수 있음
- 관계형 데이터베이스의 종류: Oracle, IBM DB2, MS SQL, MySQL 등
- 관계형 데이터베이스 테이블 구조 예시 - 영화 평점 테이블 구조

관계형 데이터베이스 장/단점
- 장점
- 다양한 용도로의 사용이 가능하며 높은 성능을 보여줌
- 데이터의 일관성이 보장
- 정규화를 통해 갱신 비용을 최소화할 수 있음
- 구조화되어 있고 동일한 구조를 가지는 데이터를 다룰 때 유리
- 단점
- 데이터 구조의 변경(칼럼의 수정이나 확장)이 어려움
- 빠른 속도를 요구하는 단순한 처리에 대응하기 어려움
- 데이터 관계는 유용하지만 그로 인한 처리 속도 저하가 발생할 수 있음
NoSQL 데이터베이스
- 말 그대로 SQL을 ‘사용하지 않는다(No)’는 의미 ( ‘SQL을 사용하는 전통적인 RDBMS가 아니다.’라는 의미로 사용되는 데이터베이스 )
- 데이터 관리를 위해 별도의 쿼리 언어나 구조는 존재함
- RDBMS의 가장 큰 특징인 테이블 형태의 데이터 구조를 사용하지 않기 때문에 형태가 고정되지 않은 비정형 데이터 처리에 유용
- NoSQL의 종류: MongoDB, Redis, Casandra, Hbase, CouchDB 등
- 데이터 구조

NoSQL 데이터베이스 장/단점
- 장점
- 대용량 데이터 처리에 유리
- 분산 처리에 적합
- 클라우드 컴퓨팅 환경에 적합
- 빠른 읽기/쓰기 속도를 제공
- 유연한 데이터 모델링(비정형)이 가능
- 단점
- 복잡한 데이터 관계를 표현할 때 중복 데이터가 발생할 수 있음
- 모든 데이터가 동일한 구조를 가지고 있지 않은 경우에 유리
- 빠른 처리 속도를 위해 필요한 데이터를 다른 테이블 등에서 참조하지 않고 데이터 자체에 포함하는 구조에 적합
- 나에게 맞는 데이터베이스 선택하기
데이터베이스의 특징 비교

대형 상용 데이터베이스(Oracle, MS SQL, IBM DB2 등)의 문제점
- 설치 과정이 복잡하거나 별도의 관리가 필요
- 설치 용량이 크고 메모리를 많이 차지
- 데이터베이스 운영 과정에서 발생하는 문제 해결에 불필요한 시간이 소요
자바 및 자바 웹용 데이터베이스
- 일반적으로 자바 및 JSP, 서블릿 등의 자바 웹 프로그래밍을 배우는 과정에서 MySQL을 많이 추천함
- 장점
- 커뮤니티 버전을 무료로 사용할 수 있음
- 설치가 비교적 간단하고 관리 도구도 제공하며, 온라인에서 많은 도움을 받을 수 있음
- 단점
- 설치 과정이 다소 복잡
- 네트워크 서버 방식으로만 운영되기 때문에 어느 정도 관리가 필요
H2 데이터베이스를 추천하는 이유
- 별도의 설치나 관리가 필요 없음(JDBC 드라이버만으로 사용 가능)
- 임베디드 모드, 네트워크, 인메모리 등 다양한 운영이 가능
- 앱 배포 시 포함이 가능
- 용량과 메모리 사용이 적음
- 표준 SQL을 모두 지원하고 JPA와의 연계도 용이
*관계형 데이터베이스
- 테이블
테이블
- 관계형 데이터베이스에서 데이터 관리의 기본 구조
- 데이터가 가지는 공통적인 속성을 모아 정의한 칼럼(필드)으로 구성
- 칼럼에 저장되는 데이터는 숫자형, 문자형, 날짜형, 불형(Boolean) 등
- 파일과 같은 바이너리 데이터를 저장하거나 매우 긴 텍스트를 저장할 수 있는 자료 형도 있음
- 예시


칼럼(Column)
- 테이블을 구성하는 기본 속성으로 필드, 어트리뷰트라고도 불림
- 각각의 칼럼에 저장되는 데이터는 동일한 타입이어야 하며 구체적인 자료형은 데이터베이스마다 차이가 있음
- 예시 - 이름, 대학, 생년월일, 이메일
로우(Row)
- 하나의 데이터셋을 의미하며 레코드 혹은 튜플이라고도 함
- 예시 - 한 사람의 데이터, 즉 김길동, AA대학교, 1999-10-21, kim@aa.com
자료형
- 칼럼에 들어갈 수 있는 데이터 유형
- 숫자형, 문자형, 날짜형, 불형(Boolean)

- 제약 조건
제약 조건(Constraint)
- 칼럼에 부여되는 일종의 속성으로 저장될 데이터에 대한 요구사항
- 제약 조건은 데이터베이스 자체적으로 저장될 데이터에 대한 요구 조건을 설정
- 따라서 제약 조건을 벗어나는 데이터는 원천적으로 차단
- 데이터베이스의 무결성(Integrity)을 지키기 위한 방법이 됨

- 키
키(Key)
- 관계형 데이터베이스의 제약 조건 중 하나
- 데이터의 유일성 및 관계 설정을 위해 사용
- 적절한 키의 사용은 데이터베이스 설계에서 매우 중요한 요소
기본키(Primary Key, PK)
- 주키, 프라이머리키라고도 불림
- 테이블에 저장된 레코드(로우)를 서로 구분할 수 있도록 특정 칼럼에 설정하는 제약 조건
- 기본키가 존재하지 않으면 데이터가 중복되고 특정 데이터 검색에 오류가 발생하기 때문에 꼭 설정되어 있어야 함
- 보통 기본키는 시퀀스(Sequence)라 불리는 단순 증가 값을 사용
- 단순 증가 값은 1부터 시작해서 1씩 단계적으로 증가하는 숫자로, 단순히 데이터를 서 로 구분하는 용도로만 사용
- 예시

- 별도의 중복되지 않는 값이 기본키로 필요
- 개인정보는 외부에 노출되 지 않는 것이 좋기 때문에 기본키로 부적합
외래키(Foreign Key, FK)
- 테이블 간의 관계를 설정하기 위해 사용하며 참조 무결성을 제공하기 위한 용도
- 데이터의 의미는 동일하지만 검색에서 문제가 발생
- 예시 - 같은 학교임에도 AA대학교 or AA 대학교 or 에이에이 대학교 등과 같이 조건 검색을 해야 하는 문제가 발생
- 이러한 문제를 원천적으로 차단하기 위해서는 등록 가능한 대학정보 테이블을 별도 로 두고 이를 참조할 수 있도록 외래키를 등록해 사용
- 예시

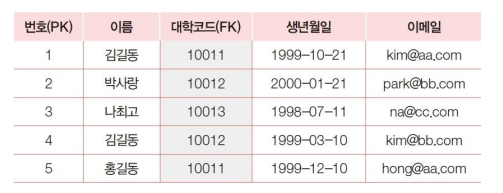
- 학생정보 테이블의 대학 칼럼에 대학정보 테이블에 없는 값을 등록하는 경우 에러가 발생하고 데이터가 등록되지 않음
- 대학코드 테이블에서 특정 대학을 삭제하는 경우 해당 데이터를 학생정보 테이블에서 참조하고 있기 때문에 단순한 삭제 쿼리로는 데이터가 바로 삭제되지 않음
- 시퀀스, 트랜잭션
시퀀스(Sequence)
- 기본키 칼럼을 관리하기 위해 사용하는 데이터베이스 객체
- 보통 데이터를 추가할 때 순차적으로 증가하는 값을 자동으로 생성
- 최근의 데이터베이스는 auto increment, auto_increment와 같은 속성을 칼럼에 추가 하는 것으로 자동 증가 값을 사용할 수 있음
트랜잭션(Transaction)
- 프로그램에서 어떤 이벤트가 발생했을 때 여러 테이블의 데이터를 차례로 변경해야 하는 경우가 많이 발생
- 예) 동일 은행의 A계좌에서 B계좌로 이체한다고 했을 때
- 계좌는 테이블로 볼 수 있음
- A계좌에서 100만 원을 차감한 후 B계좌에 100만 원을 추가하면 계좌이체가 완료됨
- 이때 A계좌에서 차감 후 B계좌에 추가하는 과정에서 에러가 발생하면 A계좌에서 차감 했던 금액은 다시 원래대로 되돌려야 함
- 이때 트랜잭션이란 하나의 논리적 기능을 수행하기 위해 여러 작업을 묶어서 처리하는 것을 의미함
- 이러한 트랜잭션은 데이터베이스 혹은 미들웨어 레벨에서 처리할 수 있어야 함
데이터베이스에서 제공하는 트랜잭션 관리를 위한 명령
- commit: 모든 데이터의 변화를 실제 적용

- rollback: 문제 발생 시 현재까지의 변화를 원래대로 되돌림

- A~C 순으로 진행되는 트랜잭션의 처리 과정
*H2 데이터베이스
- H2 데이터베이스란?
H2 데이터베이스
- 임베디드 데이터베이스 / 관계형 데이터베이스 관리 시스템
- 설치가 필요 없으며 데이터베이스 파일만 있으면 언제든지 데이터 베이스를 실행할 수 있어 프로그램에 포함해서 배포하는 것도 가능
- 운영 데이터베이스와 상관없이 관계형 데이터베이스를 사용
- 특정 데이터베이스 종속 기능 없이 구현하는 경우 H2와 같은 경량 데이터베이스를 이용해 개발하기도 함
H2 데이터베이스 의 세 가지 모드
- 임베디드 모드
- 프로그램에서 JDBC URL을 이용해 접속하거나 console 웹을 통해 관리
- 데이터 파일만 있으면 동작
- 가장 간단하고 지정된 데이터 파일이 없다면 자동 생성하므로 언제든 실행 가능
- 톰캣이 실행된 상태에서는 별도의 도구를 통해 데이터베이스 관리가 불가능
- 파일을 사용하기 때문에 동시 다중 접속이 불가능하므로 개발이나 테스트가 불편
- 인메모리 모드
- 프로그램에서 JDBC URL을 이용해 접속하거나 console 웹을 통해 관리
- 데이터베이스를 메모리상에서만 운영하는 모드로 처리 속도가 빠름
- 프로그램 종료 시 데이터가 소멸되기 때문에 일반적인 애플리케이션에는 부적합
- 네트워크 서버 모드
- H2 데이터베이스를 내려받아 설치한 후에 JDBC를 이용해 접속하거나 console 웹을 통해 관리
- 일반적인 데이터베이스와 같이 네트워크 서버로 동작하는 방식
- 동시 다중 접속이 가능
- 별도의 프로그램 실행과 관리가 필요하기 때문에 데이터베이스 서버를 별도로 실행 해야 함
- H2 설치
H2 데이터베이스 설치하기
- H2 자체가 자바로 구현되어 있기 때문에 H2 데이터베이스 실행을 위해서는 자바가 설치되어 있어야 함
- H2 데이터베이스 홈페이지(https://www.h2database.com/)에 접속하여 최신 버전 (1.4.2)의 H2 데이터베이스를 내려받아 설치
- 내려받은 설치 프로그램을 실행하면 C:\Program Files (x86)\H2에 설치됨
- 설치가 완료되면 윈도우 시작 버튼을 누르고앱을 실행함. 앱이 실 행되면 자동으로 웹 기반의 관리 콘솔 화면이 뜸. 이때 윈도우 트레이의 H2 아이콘 에서 마우스 오른쪽 버튼을 클릭하여 ‘Create a new database...’를 선택
- 데이터베이스 생성 화면에서 다음 내용을 참조해 원하는 이름으로 데이터베이스를 생성함. 작성을 완료한 후 버튼을 눌러 DB를 생성하기
- 이때 Database path는 실제 데이터 파일이 생성되는 경로와 파일명이므로 신중히 작성
- 정상적으로 데이터베이스가 생성되었으면 다시 콘솔 화면으로 돌아와 연결 시험을 수행
- 사용자명, 비밀번호를 넣은 다음 <연결 시험> 버 튼을 눌렀을 때 ‘시험 성공’이 나오는지 확인하기
*SQL의 개요
-SQL이란?
SQL(Structured Query Language)
- 관계형 데이터베이스에서 데이터를 관리하기 위한 쿼리 언어
- 대부분의 프로그래밍 언어보다는 단순한 구조
- SQL 자체는 표준 언어이지만 데이터베이스마다 세부적인 차이가 있을 수 있기 때문에 데이터베이스와 호환이 되지 않을 수도 있음
- SQL은 단순히 데이터 관련 작업 이외에 데이터베이스 자체의 관리 기능 수행에도 사용됨
SQL에서 할 수 있는 일
- 새로운 테이블 생성
- 내장 프로시저Stored Procedure 생성
- 뷰 생성
- 테이블, 프로시저, 뷰 등의 접근 권한 부여
- 데이터베이스에 대해 쿼리 실행
- 데이터베이스로부터 데이터 조회
- 데이터베이스에 기록 삽입, 갱신, 삭제
- 새로운 데이터베이스 생성
- SQL의 유형
DDL(Data Definition Language)
- 테이블의 생성, 수정, 삭제와 같은 관리 기능을 제공하는 SQL 문
- 스키마, 테이블, 시퀀스, 인덱스, 사용자, 권한 객체를 생성하고 관리하기 위한 명령
DML(Data Manipulation Language)
- 테이블의 데이터를 조작할 때 사용하는 SQL 문
- 데이터 조작의 기본 기능인 CRUD(Create, Read, Update, Delete)와 관계된 명령으로 이루어짐

H2의 대표적인 자료형

SQL의 기본 규칙
- 모든 SQL 구문과 식별자는 대소문자를 구분하지 않음
- 데이터베이스에 따라 구분하는 경우도 있음
- 명령과 키워드는 대문자, 식별자는 정해진 이름 규칙에 따를 것을 권장함
- 식별자는 영문으로 작성하며 공백을 허용하지 않음
- 키워드는 식별자로 사용할 수 없음
- 서술적인 접두어 사용은 자제함
- 예) tbl_member, idx_, pk_
- DDL이란?
DDL의 종류
- 테이블의 생성, 수정, 삭제와 같은 관리 기능을 제공하는 SQL 문을 의미
- DDL을 통해 데이터베이스 스키마, 테이블, 인덱스 등 데이터 저장 및 운영을 위한 객체의 생성과 관리가 가능
- CREATE, ALTER, DROP, SHOW
CREATE
- 테이블을 생성
- 각 칼럼의 자료형과 최대 크기를 명시해야 함
- 칼럼에 제약 조건과 속성을 추가할 수 있음
- 마지막 칼럼 설정 뒤에 ‘,’를 넣지 않도록 주의

ALTER
- 테이블 구조를 수정
- 테이블에 데이터가 들어가 있는 상태에서는 구조 변경에 여러 제약이 따름
- 칼럼의 자료형은 변경할 수 없음
- 칼럼의 크기를 줄일 수는 없고 늘리는 것만 가능
- NOT NULL 속성을 갖는 필드는 추가할 수 있으나, NULL 속성이 있는 필드는 추가할 수 없음
- 테이블을 수정하기 전에 신중히 테이블을 생성하는 것이 좋음

DROP
- 테이블 자체를 삭제
- 데이터와 함께 테이블과 연관되어 정의된 인덱스, 룰, 트리거, 제약 조건도 함께 삭제 되므로 주의해야 함

- RESTRICT: 기본값으로 삭제 테이블이 다른 곳에서 참조되고 있다면 삭제를 중지함
- CASCADE: 삭제 테이블과 의존관계가 있는 모든 개체를 함께 삭제

SHOW
- 테이블 정보를 조회하기 위해서는 데이터베이스마다 제공되는 별도의 명령 혹은 스키마 구조에 접근하는 쿼리를 사용해야 함
- H2 - SHOW 명령어

- DML이란?
DML의 종류
- 데이터를 조작
- 데이터의 입력, 수정, 삭제, 검색 등에 사용
- 주로 프로그램 코드 안에서 사용하는 쿼리문
- INSERT, SELECT, DELETE, UPDATE
INSERT
- 데이터를 추가
- 전체 칼럼값을 모두 추가하는 경우
- VALUES에 오는 값의 순서는 테이블을 생성할 때 지정한 칼럼 순서와 반드시 일치해야 함

- 부분 칼럼 데이터만 저장하는 경우
- NOT NULL 칼럼은 반드시 포함되어야 하며 auto_increment 속성이 적용될 칼럼은 비움

SELECT
- 데이터를 조회
- 전체 데이터 혹은 조건에 맞는 데이터만 조회가 가능
- 데이터베이스에서 제일 중요한 쿼리
- 효율적인 조회를 위한 작업
- 여러 테이블의 데이터를 조합해서 조회
- 외래키 칼럼의 코드 데이터를 참조 테이블의 이름 칼럼으로 대체
- 날짜 형식 변경
- 데이터 정렬 또는 집계
SELECT를 통한 단일 테이블 조회

- 특정 칼럼을 지정하거나 전체 칼럼(*)을 조회할 수 있음
- DISTINCT: 중복된 값은 제거하고 가지고 옴
- WHERE: 검색 조건을 지정할 때 사용

- GROUP BY: 특정 칼럼을 그룹화할 때 사용
- HAVING: 특정 칼럼을 그룹화한 결과에 조건을 설정할 때 사용
- ORDER BY: 특정 칼럼을 기준으로 오름차순(ASC)/내림차순(DESC) 정렬할 때 사용
- 데이터 조회 함수
데이터 조회 함수란?
- 데이터 조회의 편의를 위해 제공되는 데이터베이스마다의 전용 함수
숫자 관련 함수
- 숫자를 조작하기 위한 함수
- ABS(절댓값), CEILING(올림), ROUND(반올림), FLOOR(버림), SQRT(제곱근) 등

문자 관련 함수
- 문자, 문자열을 조작하기 위한 함수
- ASCII(아스키코드값), LENGTH(길이), CONCAT(문자열 결합), TRIM(양쪽 공백 제거)
- LOWER(소문자 변환), UPPER(대문자 변환), SUBSTRING(부분 선택) 등

날짜/기간 함수
- NOW(현재 날짜 시간), CURRENT_TIMESTAMP(현재 날짜 시간), DAYNAME(요일)
- PARSEDATETIME(문자열 포맷을 날짜 시간 정보로 변환) 등

집계 함수
- COUNT(레코드 수), SUM(칼럼값 더하기), AVG(칼럼값 평균)
- MAX(칼럼 최댓값), MIN(칼럼 최솟값) 등

- 조인
조인(Join)
- 관계형 데이터베이스에서 2개 이상의 테이블이나 데이터베이스를 조합해 데이터를 검색하는 것
- 조회하고자 하는 칼럼이 서로 다른 테이블에 있을 경우에 주로 사용
- 여러 개의 테이블을 마치 하나의 테이블인 것처럼 사용할 수 있는 방법
- 기본키(PK)와 외래키(FK)로 연결된 두 테이블의 데이터를 조합하기 위해 사용할 수 있음
- 조인은 여러 유형이 있으며 조인을 통해 여러 번 쿼리를 보내거나 결과를 프로그램 에서 조합할 필요 없이 한 번의 쿼리로 원하는 데이터 구조를 받아볼 수 있음
- 조인 형태: Inner Join, Outer Join, Cross Join, Self Join 등
*JDBC 기본 구조와 API의 이해
- JDBC의 개념
JDBC의 등장 배경
- 데이터베이스의 종류가 다양하기 때문에 개발에 많은 어려움이 있음
- JDBC(Java DataBase Connectivity) - 자바 애플리케이션에서 표준화된 방법으로 다양한 데이터베이스에 접속할 수 있도록 설계된 인터페이스
- 개발자는 각 데이터베이스에 대해 자세히 알지 못해도 JDBC API만 알면 모든 데이터베이스에서 동작할 수 있는 애플리케이션을 개발할 수 있음
- 응용 프로그램에서는 자바에 기본적으로 포함된 JDBC API(인터페이스로 규격만 정 의하고 있음)를 사용해 프로그램 코드를 작성하고 실제 데이터베이스 연결은 각 데이터베이스 회사가 제공하는 JDBC 드라이버(JDBC API 구현 클래스)를 이용해 SQL 문으 로 데이터를 조작하는 형태로 동작함
JDBC의 구조
- JDBC API: 응용 프로그램에서는 자바에 기본적으로 포함된 JDBC API를 사용해 프로 그램 코드를 작성함
- JDBC 드라이버(JDBC API 구현 클래스): 실제 데이터베이스 연결은 각 데이터베이스 회사가 제공하는 JDBC 드라이버를 이용
- SQL 문으로 데이터를 조작하는 형태로 동작

- JDBC 드라이버 설치
JDBC 드라이버
- 자바 인터페이스로 정의된 일종의 규격이기 때문에 실제 구현된 클래스가 없으면 동작하지 않음
- 이때 실제 구현된 클래스를 JDBC 드라이버라고 부르며 라이브러리와 같은 개념임
- JDBC API를 사용하는 프로그램을 개발하거나 실행하는 과정에 해당 라이브러리가 반드시 필요( pom.xml에 의존성을 추가하면 자동으로 프로젝트에서 참조됨)
- JDBC 드라이버는 보통 데이터베이스를 만드는 회사에서 직접 배포함
이클립스에 H2 데이터베이스 드라이버를 추가하기
- ‘pom.xml’의 <dependencies>...</dependencies> 사이에 다음과 같이 H2 데이터 베이스 의존성을 추가

- 파일을 저장하면 자동으로 h2 라이브러리 다운로드 과정이 백그라운드로 진행됨
- [Java Resources] → [Libraries] → [Maven Dependencies]에 ‘h2-1.4.200.jar’이 추가 되어 있으면 정상적으로 등록된 것임
- JDBC 프로그래밍
JDBC 프로그래밍의 기본 단계와 사용 클래스

① 1단계: JDBC 드라이버 로드
- 먼저 해당 데이터베이스의 JDBC 드라이버를 로드해야 함
- JDBC 드라이버를 로드하는 방법
- jdbc.drivers라는 시스템 환경 변수에 등록된 내용으로 하는 방법
- Class.forName( ) 메서드를 이용해서 직접 해당 클래스를 로드하는 방법
- 대부분의 경우 다음 코드와 같이 Class.forName( ) 메서드를 사용

- 드라이버 로드에 사용되는 org.h2.Driver는 H2 데이터베이스의 드라이버 클래스로 이름을 잘못 명시하면 오류 발생
② 2단계: 데이터베이스 연결
- 드라이버가 로드되면 해당 데이터베이스의 JDBC 드라이버를 이용해 프로그램을 작성할 수 있는 상태가 됨
- 실제 데이터베이스와 연결하려면 Connection 클래스의 인스턴스가 필요함
- DriverManager.getConnection( ) 메서드를 이용해서 Connection 클래스 인스턴스 레퍼런스를 가져올 수 있음
- JDBC 클래스 로딩과 URL이 준비되었으면 실제 데이터베이스와의 연결을 만들기 위한 코드를 작성

- JDBC URL, DB 사용자 아이디/비밀번호가 필요함
- JDBC URL: 해당 데이터베이스에 맞게 미리 정의되어 있는 문자열로 데이터베이스에 대한 다양한 정보를 포함함
- DB 사용자 아이디/비밀번호 : 데이터베이스에 등록된 계정
- JDBC URL 구조

- H2의 경우 DB 실행 방식에 따라 다음과 같은 형식을 취함

③ 3단계: Statement 생성
- 데이터베이스와 연결을 한번 완료하면 이후 연동부터는 SQL 문을 통해 이루어짐
- 문자열로 이루어진 SQL 문을 JDBC에서 처리할 수 있는 객체로 변환해야 함 => Statement 객체 사용
- 하지만 보통 SQL 문과 데이터를 조합하기 때문에 일반 Statement보다는 Statement 를 상속받는 PreparedStatement를 사용하는 것이 좋음
- PreparedStatement
- SQL 문을 미리 만들어두고 변수를 따로 입력하는 방식
- 효율성이나 유지보수 측면에서 유리한 구조
- 기본적으로 Statement 클래스를 상속받기 때문에 Statement 클래스 메서드를 모두 사용할 수 있음

④ 4단계: SQL문 전송
- PreparedStatement 객체가 준비되면 실제 쿼리의 실행은 SQL 문 종류에 따라 executeQuery( ) 혹은 executeUpdate( )를 사용하게 됨
- executeQuery( )
- SELECT 문을 수행할 때 사용
- 반환값은 ResultSet 클래스 타입으로, 해당 SELECT 문의 결과에 해당하는 데이터에 접근할 수 있는 방법을 제공
- executeUpdate( )
- UPDATE, DELETE와 같은 문을 수행할 때 사용
- 반환값은 INT 값으로, 처리된 데이터의 수를 반환
⑤ 5단계: 결과 받기
- 데이터베이스에서 데이터 결과를 받으려면 Statement나 PreparedStatement의 execute Query( )를 사용
- 입력, 수정, 삭제와 달리 데이터를 갖고 오는 경우에는 가져온 결과 데이터를 처리하기 위한 ResultSet 객체가 필요
- ResultSet은 조회한 결괏값에 순차적으로 접근할 수 있는 커서를 다룰 수 있게 함

⑥ 6단계: 연결 해제
- 데이터베이스 사용이 종료되면 기본적으로 연결을 해제해야 함
- 데이터베이스는 동시에 여러 연결을 지원하지만 동시 연결 수에 따라 라이선스 비용이 증가하기도 하고, 동시 연결 가능 수가 적은 경우 대기 시간이 길어지는 문제가 발생하기도 함
- 사용이 끝난 데이터베이스와의 연결은 해제해주는 것이 좋으며 하나의 연결 에서 발생하는 여러 Statement, ResultSet 같은 객체도 종료해주는 것이 좋음.

'개발 공부 > Java' 카테고리의 다른 글
| [JSP/스프링] - REST API 개발 (0) | 2024.01.15 |
|---|---|
| [JSP/스프링] - 리스너와 필터 (0) | 2024.01.12 |
| [JSP/스프링] - MVC 패턴의 이해 (0) | 2024.01.09 |
| [JSP/스프링] - JSP 응용 (0) | 2024.01.08 |
| [JSP/스프링] - JSP의 기초 (0) | 2024.01.05 |